Segmenting Overlapping Chromosomes using Deep Learning
After my last post on optimization of earnings by cab drivers as they drive through New York City – this post explores using deep learning aka Artificial Intelligence to segment out overlapping chromosomes on slides used for cytogenetic studies. The project is part of a set of open problems posted on AI ON website. The repo for the project is also available on my GitHub. We’re still working on it and would love if any of you would like to join and contribute !
Cytogenetics
Cytogenetics is the study of cells, more so chromosomes and their structure and changes.Changes to chromosome structure can disrupt genes, causing the proteins made from disrupted genes to be missing or faulty. Depending on size, location, and timing, structural changes in chromosomes can lead to birth defects, syndromes or even cancer.
The importance of separating overlapping chromosomes can be understood in terms of the orders of difficulty involved in manually segmenting them. In cytogenetics, experiments typically starts from chromosomal preparations fixed on glass slides. Occasionally a chromosome can fall on another one, yielding overlapping chromosomes in the image. Before computers and images processing with photography, chromosomes were cut from a paper picture and then classified (at least two paper pictures were required when chromosomes are overlapping). More recently, automatic segmentation methods were developed to overcome this problem. Most of the time these methods rely on a geometric analysis of the chromosome contour and require some human intervention when partial overlap occurs.
Semantic Segmentation & U Net
Semantic segmentation for computer vision refers to segmenting out objects from images. Semantic because objects need to be segmented out with respect to surrounding objects/ background in image. That is, algorithm should be able to segment a tree even if it’s taken close-up or at some distance, and not based on absolute cor-ordinates of the object in the image.

So if a net needs to segment out a tree – it would first need to understand what features of an object make it look like tree. Like leaves, branches stem and in a particular arrangement - leaves on branches, branching out from trunk only makes it look like a tree. But only understanding features won’t help – it would need to map the features learnt to an image and segment only the matching part – to mark out a tree.
This is exactly what a U Net does – it uses convolutional feature maps to first learn the features as it progressively downsamples the image size. After that, the learnt feature maps are progressively upsampled and in each step they are merged with feature maps of same size from the downsampling phase. The merging step helps the net to spatially place the learn features back into the image.
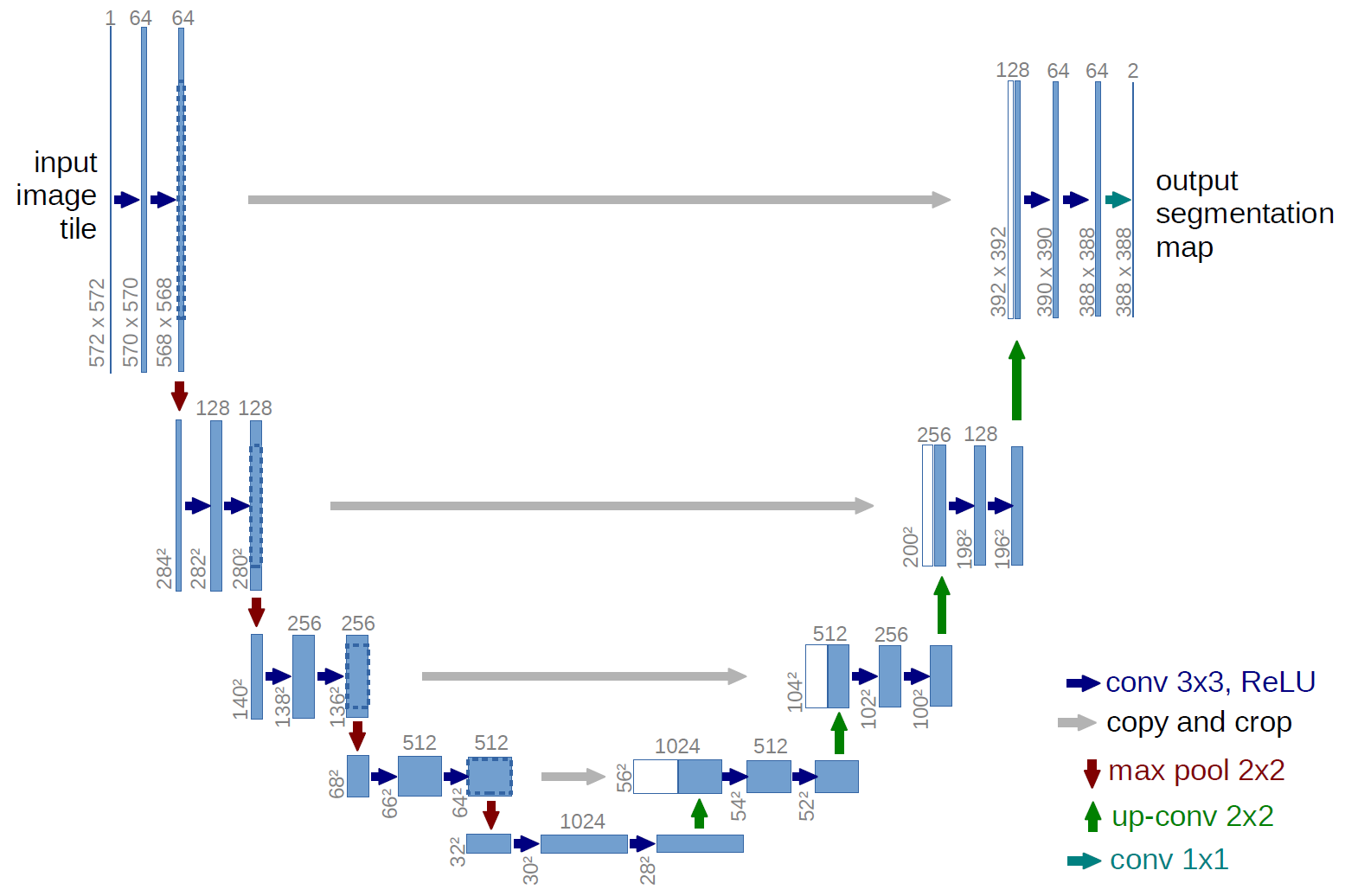
As the image above explains,input image consist of 3 channels (RGB) and is passed through 3 convolutional layers before being downsampled to half the size. After extracting enough features, with dimensions of 28 x 28, they maps are upsampled and in each step merged with the feature map of the corresponding step in downsampling path.
Training Methodologies
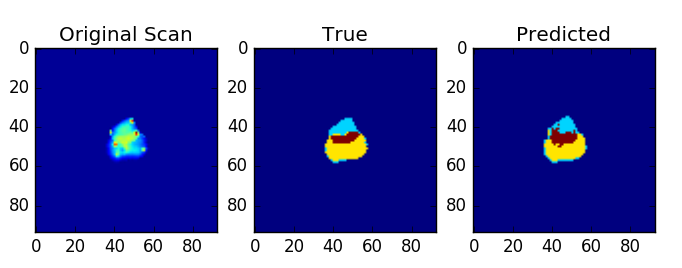
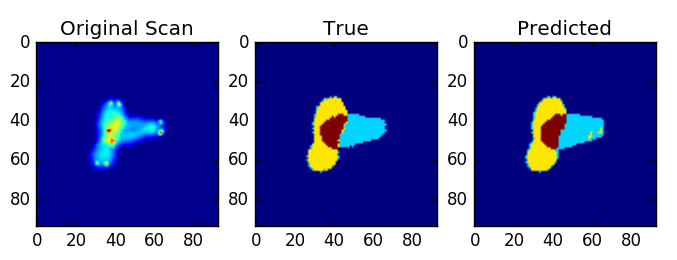
Each of the annotated images consists of 4 classes, where class 4 is the common region between 2 overlapping chromosomes. The classes 1 & 2 , are non-overlapping part of each of the chromosomes. Class 0 is the background The performance of the net was observed using mean_dice_score. It was computed as
dice_score = 2*I/(GT + PL)I = number of pixels predicted correctly except background
GT = number of pixels which belong to ground-truth except background
PL = number of pixels in predicted image except background.
There were 2 methods of training attempted
• Treating all the classes independently (param combine_label = True in segmentation.py)
• Treating Class 1 & Class 2 as same i.e. Class 1 and Class 3 as Class 2 (param combine_label = False in segmentation.py)Assumption being the non-overlapping parts inherently aren’t different in each chromosomes. Then we can apply conventional CV methods like watershed algorithm to distinguish between the non-overlapping blobs
Results
The results looked a lot of promising where my validation set was first 200 images from 20% of the total dataset. With combined labels, could reach a dice score as high as 0.97. Without combined labels, could reach a dice score as high as 0.81.
Predictions for combined_label
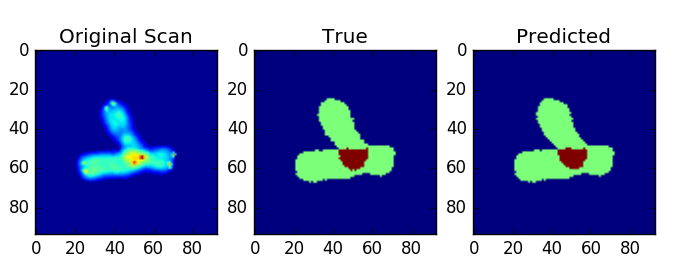
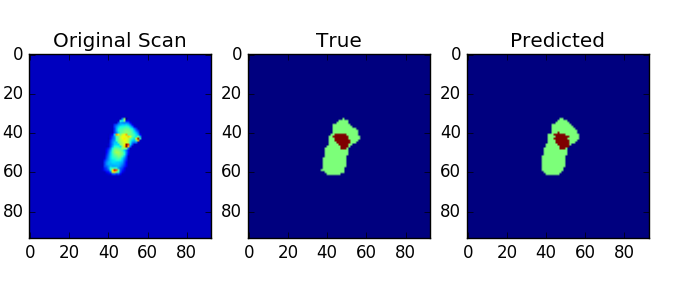
Predictions without combining labels