Is unsupervised learning the way forward ?
Of late, we have heard a lot of talk about unsupervised learning being the way forward. Before we delve further, let’s clear the air around the types of learning.
Supervised learning : Learning, wherein the model is provided with target labels. The model is trained to predict the labels. E.g. Detecting digit from a hand-written image, given similar training data with labels (i.e. mapping of every image in training set to a corresponding label)
Unsupervised learning : Exact opposite of above, that is, no labels are provided for training. E.g. Detecting from various images of hand-written digits, images of ‘1’ & ‘7’ are different categories.
There is another category - semi-supervised learning. More on it later. So unsupervised seems easy, right ? So exactly why this hype around unsupervised learning ?
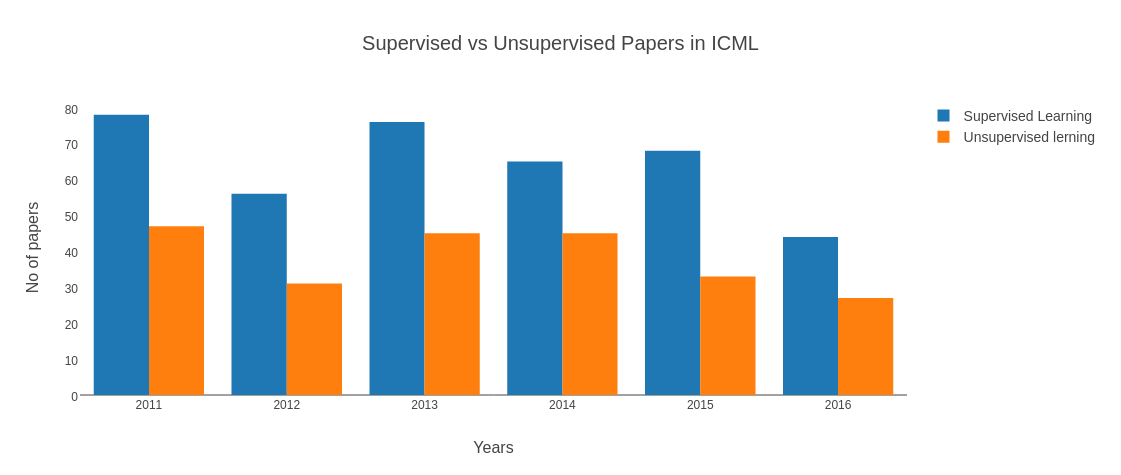 Fig: No. of ICML papers on supervised & unsupervised learning
Fig: No. of ICML papers on supervised & unsupervised learning
Well, going by trends of ICML papers (pic above), it very well proves that focus of all the deep learning research has been around supervised learning all this while. Apparently it turns out that unsupervised learning could in fact actually be holding the key to future. Reasons being
-
Anotation is costly and hence rare - Annotation refers to labelling such as marking out the boundary of each pet in a picture of pets and then labelling them with corresponding category of pet. Hence, annotation for images and text is costly because of higher man-hours needed to annotate each example. Even though annotation platforms like AMT have arrived to rescue, annotated datasets are tough to obtain for most of the applications
-
Pre-training to reduce dimensionality : As anyone slightly familiar with training nets would confirm, converging deep supervised nets is tougher in higher dimension space - mostly because of overfitting in a large parameter space. As per findings by Prof Begio, models that start off with some unsupervised learning to reduce dimensionality tend to have lower variance. Hence, those models are more robust to random initialisations. He illustrates in the paper, models that start with parameters learnt from unsupervised nets tend to lock in parameter spaces which aren’t achievable by supervised nets and vice-versa
-
Supervision not desirable : For a lot of use-cases like generating images, generating audio - there’s really no ‘correct’ answer. To replicate human-like capabilities like creativity, behavior with other machines - where we want to simulate human like capabilities in civilisation of machines - it’s desirable that the machines aren’t trained with a correct way of behavior, as that defeats the purpose of simulation
-
Labelling not accurate - As humans we do err. When it comes to easier object segmentation like cat, dog - there’s hardly any error. But when it comes to annotation of complex bio-medical images it isn’t easy for trained radiologists to annotate easily. So for most labelled public datasets, labelling is done multiple times over by separate viewers and majority vote is taken for final categorisation.
So given that we understand the importance of unsupervised learning, let’s have a look at some of the most popular unsupervised algorithms in various fields of applications.
Word Embedding
- Applications
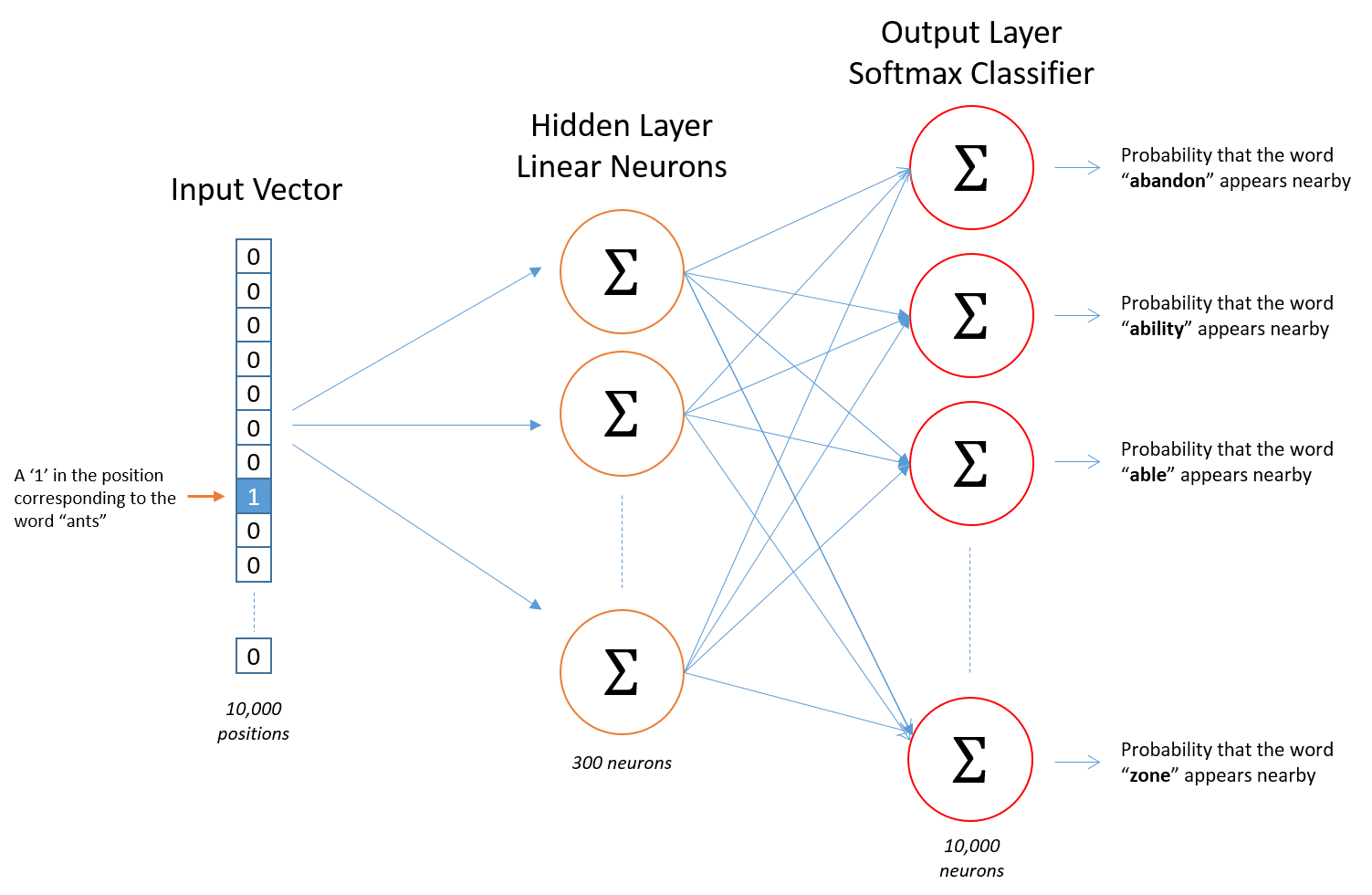
- Word2Vec is normally used for building semanti representation of words in a latent space based on features such as occurrence of a word in a sentence, co-occurrence with other words etc.
- Architecture
- Word embedding algorithms like Word2Vec use shallow 2 layer neural networks, that take in a corpus of input and produces a vectorial representation of each word in some high-dimensional latent space. The algorithm learns from a semantic vectorial representation of each of the words. It can thus easily predict
- Variants
- Doc2Vec, GloVe
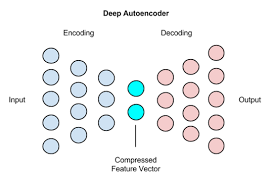
AutoEncoders
- Applications
- For pre-training purposes, the output of the encoder (in a much lower dimension space) is generally used as a good proxy for the original input
- Architecture
- AutoEncoders generally contain 2 parts to the architecture - encoders and decoders, placed sequentially. They are trained to predict the input itself. Encoder part takes in the raw input and downsamples in successively lower dimensional space as the no of neurons in each layer goes down with increase in layer depth. Decoder part takes in the output of encoder and upsamples into higher dimensional space successively as neurons in each layer increases with depth. Final output of decoder is in the same dimension as the input given to the encoder.
- Variants
- Variaional AEs, Denoising AEs
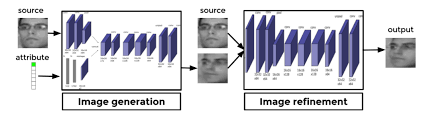
Generative Adversial Networks
- Applications
- GANs are normally used for generating dreams, filling in missing patches of images, extrapolating background from images.
- Architecture
- Generative Adversial Nets generally also consists 2 parts - generator networks and discriminator nets. The generator nets generates say images from just Gaussian noise signal as input. The discriminator is shown the output from generator net along with 'real' images and trained to discriminate between real and 'fake generated' images. The error signal from prediction is backpropagated back through the gnerative net as well. Thus over the epochs, the discriminator becomes good at identifying 'real' from 'fake generated' images while generator net becomes good at generating a near-real image.
- Variants
- DCGAN, GAN